Self - Learning Supply Chain
Self Learning Supply Chain
Self - Learning Supply Chain
Self Learning Supply Chain
New trend of building Self -Learning Supply Chains
The world's most innovative companies have two common characteristics: superior products and supply chains that use advanced data analytics.
These design, data and knowledge masters have supply chains that are more flexible and responsive than competitors.
Gartner reports that 70% of companies use only descriptive data analytics (describing the past state), 15-25% use predictive data analytics (describing future status), and only about 1-5% use prescriptive data analytics (advising users what steps to do in follow-up to the analysis of hidden trends in data).
Companies without prescriptive data analytics get into problems with poor product design, inaccurate estimates, inefficient planning and waste. They are limited by descriptive analytics looking into the past, needing to move from "What happened?" to "What's happening?" and "What steps should we take?"
The traditional supply chain is based on a number of assumptions based on human experience and rules, such as an estimate of production time in the process or adjustment time of the machine. This leads to inaccuracies that lead to unreliable plans. It starts with a small deviation - technological operation takes longer than planned - and soon due to the domino effect of accumulating inaccuracies, the whole plan is invalid.
By contrast, the self-learning supply chain learns business processes through a continuous analysis of historical data and generates predictions of key performance indicators and recommendations to improve process planning. For example, it captures the difference between planned and ongoing tasks, analyzes the cause of this difference, and uses this knowledge in future planning to reduce this deviation.
Estimation of production time of individual operations in the technological process.
Inaccuracies in the technological time estimates are then accumulated in the unreliable production plans.
Three steps of the Self -Learning Supply Chain process - step 1: getting data
Data from production terminals.
Data from manufacturing terminals and sensors on machines in the timeline.
Deleting data noise caused by sensors and other noise sources using digital filters in the Matlab Signal Processing Toolbox.
Three steps of the Self - Learning Supply Chain - step 2: getting knowledge
Deep Machine Learning
Deep Machine Learning teaches computers to do what people and animals do naturally - learning from experience. Machine Learning algorithms use computational methods to "learn" information directly from data without relying on a predefined model. Algorithms are adaptively improving their performance with an increasing number of data. Algorithms analyze historical data from overdue production cycles, and identify hidden patterns in millions of data points that people are unable to capture, such as relationships between order characteristics and setup times and production cycle times or any other measurable data.
The system will include Deep Neural Convolutional Networks that simulate brain processes using an artificial neural network that has many nested layers where output from one layer node is a nonlinear combination (convolution) of all inputs from the previous layer.
We will connect Deep Machine Learning with Reinforcement Learning and create a system that will teach itself to recognize the subtle patterns in a large quantity of data coming from the supply chain and combine actions (for example, adjusting the time of the manufacturing operation) with results (such as timely delivered product to the customer). The software will have access to real-time up-to-date supply chain data and will be essentially told: "Get them to learn how to maximize resources utilization and productivity."
Reinforcement Learning
During Reinforcement Machine Learning, a software agent performs observations and takes action in the environment and receives rewards in return. Its goal is to learn how to maximize expected long-term rewards. In short, the agent works in the environment and learns by trial and error to maximize his rewards and minimize his loss.
An agent can be a program that tracks real-time up-to-date supply chain data and decides how to adjust, for example, the time of the production operation to earn a positive reward, for example, when approaching the target values of key KPI performance indicators and negative rewards when KPIs are below a certain minimum value.
The algorithm used by the software agent to determine his actions is called his strategy. For example, a strategy may be a neural network that receives real-time updated data from the supply chain and derives an action to be taken.
Neural network in the brain.
Artificial convolutional deep neural network.
Reinforcement Learning.
A game that no one can explain - overcoming Polanyi's paradox
Learning to play the strategic Go game (originated 2,500 years ago in China) has always been difficult - Confucius advised that "gentlemen should not waste time with trivial games - they should study Go," but programming a computer for this game seemed impossible.
It is estimated that the standard Go card is about 2 × 10 to 170 possible positions - more than the number of atoms contained in the universe, and Go players are unable to describe how they handle this enormous complexity of play - a situation described in the 20th century by mathematician Michael Polanyi: "We know more than we can say. "- this Polanyi paradox was an insurmountable obstacle to Go programming - how to write a program that contains the best strategies for playing a game when no one can formulate these strategies?
In October 2016, Google's DeepMind, a London based Google´s subsidiary specialized at Deep Machine Learning defeated with its AlphaGo application using the deep neural networks 4 - to - 1 Lee Sedol from South Korea - Go world champion - and overcame Polanyi's paradox. Sedol after defeating said: I'm helpless. . . I have extensive experience with Go playing but I have never been under such pressure. "
The Lee Sedol style was described as "Intuitive, Unpredictable, Creative, Intense, Wild, Complicated, Deep, Fast, Chaotic" - characteristics that give him a definite advantage over any computer.
Still, Lee Sedol was defeated because DeepMind did not program AlphaGo with superb Go strategies and heuristics. Instead, they used the Deep Machine Learning power to Reinforcement Learning to create a system that taught itself. AlphaGo has been created to recognize the fine patterns that occur in a large amount of data, and to link events (such as playing a stone to a specific place on the board) with results (such as winning the Go game). The software had access to 30 million game positions from the online store, and it was basically told, "Use them to find out how to win."
The victory of artificial intelligence over the world champion in Go means overcoming Polanyi's paradox and bringing new possibilities in the use of deep convolutional neural networks in self-learning supply chains.
Three steps of the Self-Learning Supply Chain Step 3: Planning and Optimization
Planning and Optimization
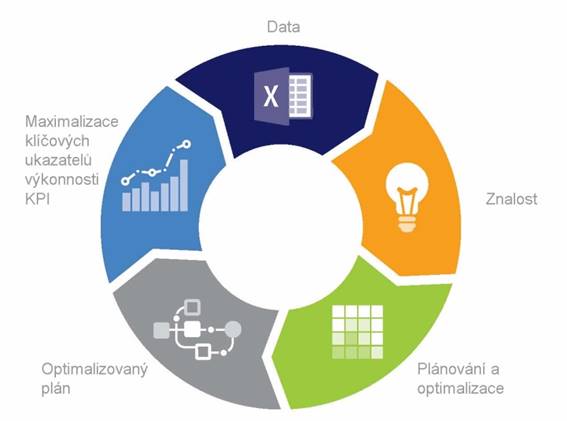
The knowledge gained by the Self-Learning Supply Chain enters Advanced Planning and Scheduling (APS). Genetic Algorithm Optimization Technologies and Darwinian Evolutionary Operators of Mutation, Selection and Crossover create plans that maximize key performance indicators (KPIs) such as Total Equipment Effectiveness (OEE). The plan is put into production, and the data acquisition, knowledge acquisition, planning and optimization cycle is repeated, leading to plans being effective and reflecting the reality of production, which increases:
Cycle of data acquisition, knowledge acquisition, planning and optimization.
An example of using the Self-Learning Supply Chain in practice
Piece production of precision engineering components with tolerances of dimensions, shapes and positions in hundredths to thousands of millimeters
Piece production of precision engineering components with tolerances of dimensions, shapes and positions in hundredths to thousands of millimeters.